Learning From Data, Problem 1.7
This post is a solution to the problem taken from Abu-Mostafa, Yaser S., Malik Magdon-Ismail, and Hsuan-Tien Lin. Learning from data. Vol. 4. New York, NY, USA:: AMLBook, 2012..
Quoted text refers to the original problem statement, verbatim.
For more solutions, see dsevero.com/blog.
Consider leaving a Star if this helps you.
A sample of heads and tails is created by tossing a coin a number of times independently. Assume we have a number of coins that generate different samples independently. For a given coin, let the probability of heads (probability of error) be \(\mu\). The probability of obtaining \(k\) heads in \(N\) tosses of this coin is given by the binomial distribution: $$ P\left[ k \mid N, \mu \right] = {N\choose k} \mu^k \left(1 - \mu\right)^{N-k} $$ Remember that the training error \(\nu\) is \(\frac{k}{N}\)
The learning model used in this chapter is the following: assume you have a \(N\) datapoints sampled independently from some unkown distribution \(\mathbf{x}_n \sim P\), targets \(y_n = f(\mathbf{x_n})\) and a set of hypotheses (e.g. machine learning models) \(h \in \mathcal{H}\) of size \(\mid \mathcal{H} \mid = M\). A coin flipping experiment is used to draw conclusions on the accuracy of binary classifiers. The \(n\)-th flip of a coin is the evaluation of some hypothesis \(h\) on point \((\mathbf{x}_n, y_n)\). Heads (numerically, 1) represents an error \(h(\mathbf{x}_n) \neq y_n\), while tails is a successful prediction. In the case of \(M\) coins, we have \(M\) hypotheses and \(NM\) data points \((x_{m,n}, y_{m,n}\))
The objective of this problem is to show that, given a large enough set of hypotheses \(\mathcal{H}\), the probability of obtaining low training error on at least one \(h \in \mathcal{H}\) is high if the data is i.i.d. Therefore, we should be careful when evaluating models even if we have followed the standard train, test and validation split procedure.
How does this translate to practice? Say you have a training dataset \(\mathcal{D}\) and \(M\) models \(h_m \in \mathcal{H}\) that you wish to evaluate. You sample (with replacement) \(N\) points \(\mathbf{x}_{m,n} \in \mathcal{D}\) (e.g. mini-batch training) for each \(h_m\) (i.e. a total of \(NM\) points). What is the probability that at least one hypothesis will have zero in-sample error?
(a) Assume the sample size \((N)\) is \(10\). If all the coins have \(\mu = 0.05\) compute the probability that at least one coin will have \(v = 0\) for the case of \(1\) coin, \(1,000\) coins, \(1,000,000\) coins. Repeat for \(\mu = 0.8\).
Let \(k_m\) be the number of heads for each coin. Since \(\nu=0\) implies that \(k=0\), we need to calculate
$$ P\left[ k_1=0 \vee k_2=0 \vee … k_m=0 \right] = P\left[ \bigvee\limits_{m} k_m = 0 \right]$$
Here, we employ the common trick of computing the probability of the complement
Note that the following step stems from the fact that \(\mathbf{x}_{m,n}\) are independent. If we had used the same set of \(N\) points for all \(h_m\) (i.e. \(\mathbf{x}_{m,n} \rightarrow \mathbf{x}_{n})\), the set of \(k_m\) would not be independent, since looking at a specific \(k_m\) would give you information regarding some other \(k_{m^\prime}\).
$$ \begin{aligned} P\left[ \bigvee\limits_{m} k_m = 0 \right] &= 1 - P\left[ \bigwedge\limits_{m} k_m > 0 \right] \\\ &= 1 - \prod\limits_{m}P\left[ k_m > 0 \right] \end{aligned} $$
Summing over the values of \(k\) and using the fact that \(\sum\limits_{k=0}^N P\left[k\right] = 1\) we can compute
$$ \begin{aligned} P\left[ k_m > 0 \right] &= \sum\limits_{i=1}^N P\left[k\right] \\\ &= \sum\limits_{i=0}^N P\left[k\right] - P\left[0\right] \\\ &= 1 - \left(1 - \mu\right)^N \end{aligned} $$
Thus, resulting in
$$P\left[ \bigvee\limits_{m} k_m = 0 \right] = 1 - \left( 1 - \left(1 - \mu\right)^N \right)^M$$
The result is intuitive. For a single coin, if \(\left(1 - \mu\right)^N\) is the probability that all \(N\) flips result in tails, the complement \(1 - \left(1 - \mu\right)^N\) is the probability that at least one flip will result in heads. For this to happen to all \(M\) coins, we get \(\left( 1 - \left(1 - \mu\right)^N \right)^M\). Similarly, the probability of the complement is \(1 - \left( 1 - \left(1 - \mu\right)^N \right)^M\) and can be interpretated as the probability that at least one coin out of \(M\) will have all flips out of \(N\) resulting in tails.
Let’s take a look at this in python.
import matplotlib.pyplot as plt
import pandas as pd
def prob_zero_error(μ: 'true probability of error',
M: 'number of hypotheses',
N: 'number of data points'):
return 1 - (1 - (1 - μ)**N)**M
d = [{'μ': μ,
'M': M,
'p': prob_zero_error(μ, M, N=10)}
for μ in [0.05, 0.8]
for M in [1, 1_000, 1_000_000]]
pd.DataFrame(d).pivot('M', 'μ', 'p').to_html()
| μ | 0.05 | 0.5 | 0.8 |
|---|---|---|---|
| M | |||
| 1 | 0.598737 | 0.000977 | 1.024000e-07 |
| 1000 | 1.000000 | 0.623576 | 1.023948e-04 |
| 1000000 | 1.000000 | 1.000000 | 9.733159e-02 |
We’ve included the results for \(\mu = 0.5\), which represents a reasonable error rate for an untrained binary classification model. The middle cell tells us that a sample of size \(NM = 10^4\) evaluated on \(M=10^3\) hypotheses (with \(10\) samples each) has a \(62.36\%\) chance of at least one hypothesis having error zero.
Let’s take a look at the asymptotic properties of \(P(N,M) = 1 - \left( 1 - \left(1 - \mu\right)^N \right)^M\) for \(\mu \in (0, 1)\).
$$\lim\limits_{M \rightarrow \infty} P(N,M) = 1$$ $$\lim\limits_{N \rightarrow \infty} P(N,M) = 0$$
Intuitvely, evaluating on more datapoints \(N\) should make it harder for all points (coins) to have zero error (tails) for any number of hypotheses. Using a larger hypothesis set \(\mid\mathcal{H}\mid = M\) is analogous to brute forcing the appearance of \(k=0\) through repetitive attempts.
If we want to bound this probability (for the sake of sanity) to some value \(\lambda\), how should we chose \(M\) and \(N\)? Solving independently for \(N\) and \(M\) in \(P(N,M) \leq \lambda\)
$$M \leq \frac{log\left(1 - \lambda\right)}{log\left(1 - \left(1 - \mu\right)^N\right)}$$ $$N \geq \frac{log\left(1 - \sqrt[M]{1 - \lambda} \right)}{log\left(1 - \mu\right)}$$
We can use these result to calculate how fast the number of hypotheses \(M\) can grow with respect to the number of datapoints \(N\) for a fixed probability of zero error \(\lambda\), and vice-versa.
(b) For the case \(N = 6\) and \(2\) coins with \(\mu = 0.5\) for both coins, plot the probability \(P[ \max\limits_i \mid \nu_i - \mu_i \mid > \epsilon ]\) for \(\epsilon\) in the range \([0, 1]\) (the max is over coins). On the same plot show the bound that would be obtained using the Hoeffding Inequality. Remember that for a single coin, the Hoeffding bound is $$P[\mid \nu- \mu \mid > \epsilon ] \leq 2e^{-2N\epsilon^2}$$
import matplotlib.pyplot as plt
import numpy as np
plt.style.use('ggplot')
N = 6
M = 2
μ = 0.5
def hoeffding_bound(ε, N, M=1):
return 2*M*np.exp(-2*N*ε**2)
def P(N, M, ε_space, μ):
k = np.random.binomial(n=N,
p=μ,
size=(1_000, M))
P = np.abs(k/N - μ).max(axis=1)
return [(P > ε).mean() for ε in ε_space]
ε_space = np.linspace(0, 1, 100)
plt.figure(figsize=(12,5))
plt.plot(ε_space, hoeffding_bound(ε_space, N), '--',
ε_space, hoeffding_bound(ε_space, N, M=3), '--',
ε_space, P(6, 2, ε_space, μ),
ε_space, P(6, 10, ε_space, μ));
plt.title('Average over $1000$ iterations of\n'
'$\max \{ \mid k_1/6 - 0.5 \mid,'
'\mid k_2/6 - 0.5 \mid\} > \epsilon $\n',
fontsize=20)
plt.legend(['Hoeffding Bound '
'($M=1 \\rightarrow 2e^{-12\epsilon^2}$)',
'Hoeffding Bound '
'($M=3 \\rightarrow 6e^{-12\epsilon^2}$)',
'$M=2$',
'$M=3$'], fontsize=18)
plt.yticks(fontsize=18)
plt.xticks(fontsize=18)
plt.ylim(0, 2)
plt.xlabel('$\epsilon$', fontsize=20);
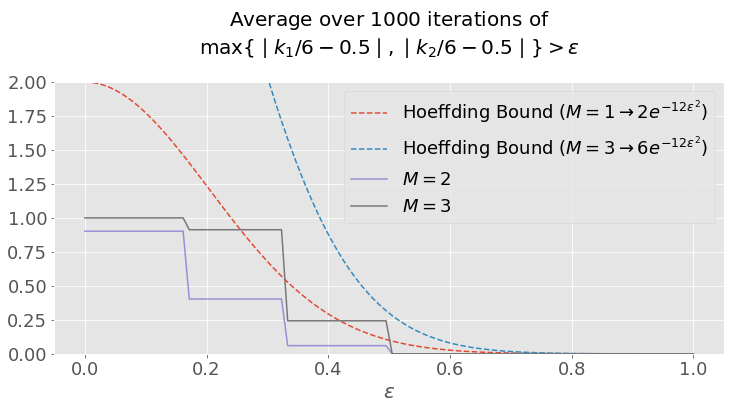
Notice how the Hoeffding Bound is violated for \(M=3\) if multiple hypotheses are not properly accounted for.
Questions, suggestions or corrections? Message me on twitter or create a pull request at dsevero/dsevero.com
Consider leaving a Star if this helps you.