
|
Ph.D. Candidate CV (last updated: October/2023) | Twitter | Google Scholar | GitHub |
Research #
My research interests are generative modelling, information theory, and compression under computational and memory constraints. Data sources usually have some type of structure, such as graphs and sets. This means we can model and compress them better by taking this structure into account. Unfortunately, existing methods that do this are either sub-optimal (don’t achieve the Shannon bound) or computationally intractable. I’m interested in building computationally efficient compression algorithms that can be used with deep generative models on structured data, as well as their connections to bayesian methods.
Originally, I am from Florianópolis (Brazil) but I’ve lived in New Jersey, Orlando, Toronto (now), São Paulo, as well as other smaller cities in the south of Brazil.
Previously, I’ve interned at the Fundamental AI Research (FAIR) lab at Meta with Karen Ullrich in the summer of 2021.
I spent 2022 at Google AI with Lucas Theis and Johannes Ballé as a Student Researcher.
Latest News #
August/2023 - I started a second internship at FAIR (Meta AI) in information theory and generative modelling with Matthew Muckley
April/2023 - Random Edge Coding and Action Matching were accepted to ICML 2023
March/2023 - Check out our ICML 2023 Workshop on Neural Compression and Information Theory
February/2023 - I was selected as a finalist for the Meta Research PhD Fellowship, 2023. Congrats to all the winners!
Selected Publications and Preprints #
For a complete list, please see my Google Scholar profile.

Daniel Severo, Lucas Theis, Johannes Ballé
Preprint, 2023

Random Edge Coding: One-Shot Bits-Back Coding of Large Labeled Graphs
Daniel Severo, James Townsend, Ashish Khisti, Alireza Makhzani
International Conference on Machine Learning (ICML), 2023

Action Matching: Learning Stochastic Dynamics from Samples
Kirill Neklyudov, Rob Brekelmans, Daniel Severo, Alireza Makhzani
International Conference on Machine Learning (ICML), 2023
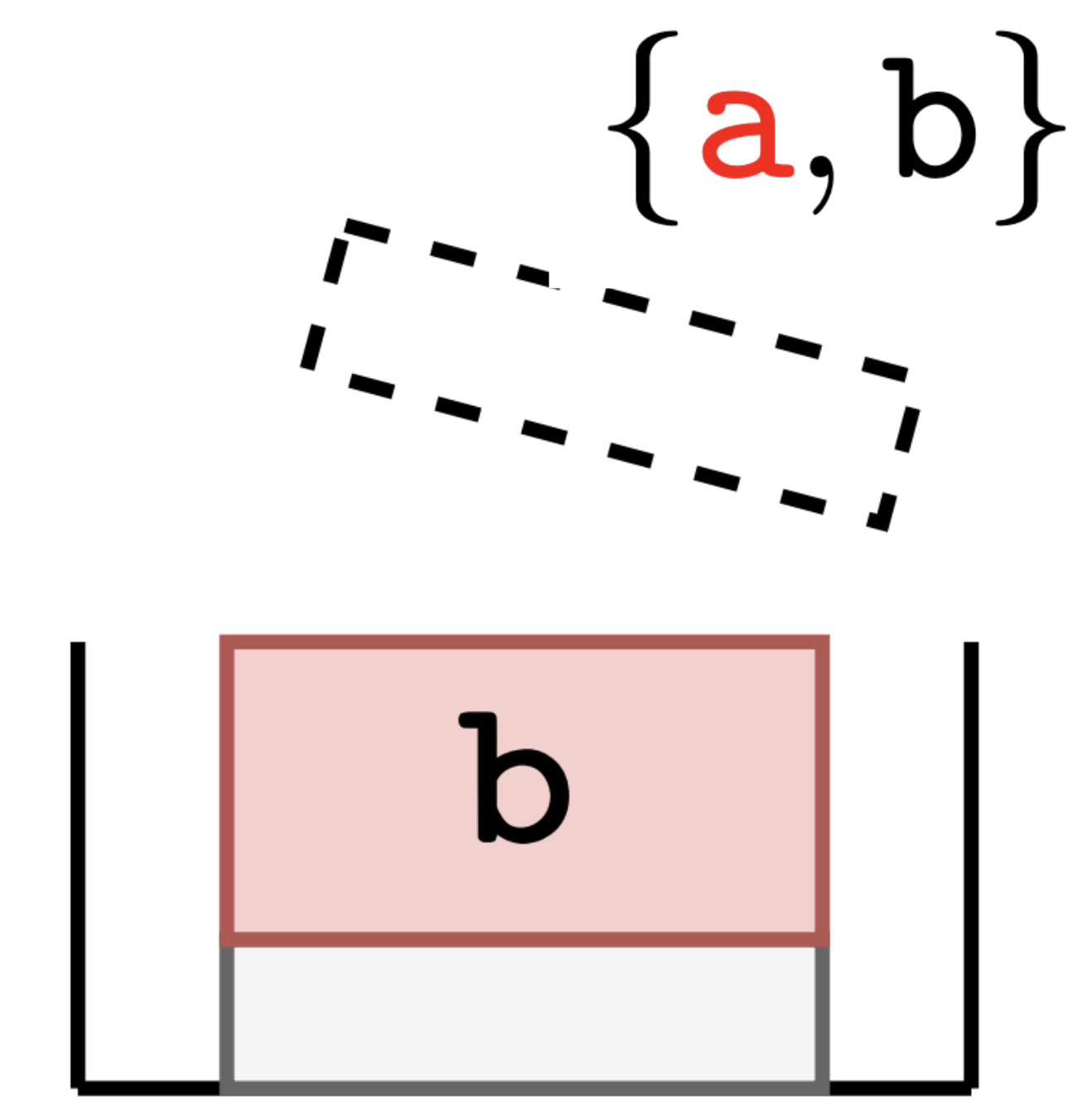
Daniel Severo, James Townsend, Ashish Khisti, Alireza Makhzani, Karen Ullrich
IEEE Journal on Selected Areas in Information Theory, 2023
Best Paper Award at NeurIPS Workshop on DGMs, 2021
Elad Domanovitz, Daniel Severo, Ashish Khisti, Wei Yu
International Conference on Acoustics, Speech, & Signal Processing (ICASSP), 2022
RCAQ: Regularized Classification-Aware Quantization
Daniel Severo, Elad Domanovitz, Ashish Khisti
Biennial Symposium on Communications (BSC), 2021
Yangjun Ruan*, Karen Ullrich*, Daniel Severo*, James Townsend, Ashish Khisti, Arnaud Doucet, Alireza Makhzani, Chris J. Maddison
Long talk at International Conference on Machine Learning (ICML), 2021
* Equal contribution
Awards #
Finalist for the Meta Research PhD Fellowship, 2023
The Meta Research PhD Fellowship program awards PhD candidates conducting research on the cusp of emerging topics across computer science, engineering, and behavioral science. To support their commitment to furthering research in some of Meta’s key interest areas, Fellows receive full coverage of tuition and university fees for up to two academic years, as well as a $42,000 stipend.
Over 3200 applicants, 62 finalists (top 2%), and 17 award winners (top 0.5%).
Vector Scholarship in Artificial Intelligence Recipient, 2020-21
The Vector Scholarship in Artificial Intelligence supports the recruitment of top students to AI-related master’s programs in Ontario. Valued at $17,500 for one year of full-time study at an Ontario university, these merit-based entrance awards recognize exceptional candidates pursuing a master’s program recognized by the Vector Institute or who are following an individualized study path that is demonstrably AI-focused.
NSERC Applied Research Rapid Response to COVID-19 Grant, 2020
Our project titled “Canadian Hospital Simulator For Management of COVID19 Cases and Contact Tracing” was awarded $75,000.00.
https://www.nserc-crsng.gc.ca/Innovate-Innover/CCI-COVID_eng.asp
Virtual Design Challenge Winner, 2019
Won 1st place at the VDC hosted by The University of British Columbia with my paper Proof of Novelty. Received a cash prize of $ 3,000.00.
https://blockchain.ubc.ca/virtual-design-challenge-authenticating-and-protecting-full-motion-videos
Student Merit Award & Medal, 2015
Science Without Borders Scholarship, 2013
Talks and Media #
- IT@UofT Source Coding with Latent Variable Models, 2021
- Two ECE grad students receive Vector Institute Scholarships in AI., 2020
- Commit 77338d2 Pursuing a Career in Data Science (pt-BR), 2020
- Hipsters #106 Cool Data Science Cases (pt-BR), 2018
You may reach me at 